Capitulo segundo.
En este capitulo veremos algunos aspectos interesantes de la shell y el uso de los comandos, conoceremos aspectos de las variables del sistema, como añadirlas como editarlas, redirección de la entrada/salida estándar de los comandos, los filtros de búsqueda, iniciación y manejo de los procesos ,entre alguna que otra utilidad .
Empecemos .
Antes de nada me gustaría mencionar un comando que a mi modo de ver es muy interesante, me refiero al comando ‘alias’, con este comando se puede dar un alias a un comando determinado .
Aqui vemos como le doy como alias a iwconfig ‘red’
rh3nt0n@rh3nt0n-laptop:~$ red
lo no wireless extensions.
irda0 no wireless extensions.
eth1 no wireless extensions.
sit0 no wireless extensions.
Cabe resaltar que el alias espira cuando cerramos la shell donde la hemos creado, pero esto es fácilmente subsanable editando el archivo ‘.bashrc’ de nuestro home, añadiendo el alias al final del archivo, este archivo se encarga de la configuración inicial de nuestra shell, y ejecuta automáticamente las ordenes que contiene al iniciar la shell .
Esto es muy bueno, por ejemplo para tema de configuraciones de red etc.
Para eliminar un alias, solo hay que ejecutar el siguiente comando:
Concatenación de comandos en la shell .
Cuando estamos utilizando la shell, podemos hacer que los comandos o aplicaciones actúen en el ‘back-ground‘ o en el ‘front-ground‘ .
Que es esto? muy sencillo, al ser linux un sistema operativo multitarea, la shell puede trabajar con muchos procesos a la vez, aunque solo se puede ejecutar un proceso cada vez mientras los demás están preparados o dormidos. Este tema de los procesos lo veremos mas adelante.
Los procesos en back-ground, son los que se ejecutan invisiblemente para el usuario y dejan libre la shell para seguir trabajando con ella.
los procesos en front-ground, son justo lo contrario, son procesos que se ejecutan en primer plano y ocupan la shell el tiempo que están en funcionamiento.
También podemos unir una serie de ordenes, e interactuar con la salida de cada orden aprovechando esa salida para que sirva de argumento para otra orden esto lo entenderemos mejor viendo unos ejemplos:
Modos de invocar ordenes:
El umpersand ‘&’, hace que esta orden se ejecute en back-ground y nos dejaría la shell libre para poder seguir usando otros comandos.
El punto y coma ‘;’ hace que se ejecuten las ordenes una a una, independientemente de que una u otra funcione.
rh3nt0n
rh3nt0n@rh3nt0n-laptop:/home$
Como se puede observar, en el anterior comando, se ejecuta ‘cd..’ y después se ejecuta ‘ls‘, sobre el directorio al que se sube con ‘cd..’
El pipe ‘|’ hace que la salida de la orden1, de argumentos a la orden 2. Ejemplo:
Estos comandos los explicare mas adelante, la orden dmesg, da los argumentos a grep para que filtre el texto especificado .
Estas comillas -“- ejecutan la orden2 que esta dentro de las comillas y pasan la salida de este como argumento a la orden1.
Aquí el resultado de uname -r daría argumentos al comando apt-get
En esta opción la orden2 se ejecutaría si orden1 termina sin errores.
En esta opción las ordenes irían ejecutándose, hasta que una de ellas se ejecute correctamente ,en ese momento se detiene.
Histórico de ordenes:
Un buen comando de ayuda en referencia a comandos, y a trabajar con ellos en la shell, es el comando ‘history‘, este comando guarda en buffer de memoria los comandos que se han ido ejecutando en la shell y con el es posible conocer cuales se han efectuado, y citarlos por su número
de orden.
1 sudo iwconfig eth0 essid j
………..
174 iwconfig
175 dmesg
176 lsusb
177 iwconfig
178 lsusb
179 dmesg
180 wget http://www.bluntmen.com/ipw2200-1.1.4-inject.patch
181 bogomips
182 yes
183 yes >/dev/null &
184 jobs
185 bg 2
186 fg 2
187 kill 2
188 jobs
189 top
190 cd .. ; ls
191 dmesg
192 history
La primera columna indica el número de comando, en el orden en el que se ha ejecutado.
La segunda evidentemente es el comando que se ha ejecutado, es una muy buena utilidad, ya que por ejemplo en comandos largos haciendo un history y fijándote en el número de orden, con solo citar el número de la forma que explicare ahora, se ejecutaría el comando:
Si por ejemplo de la lista anterior queremos hacer el número 180, haríamos lo siguiente:
rh3nt0n@rh3nt0n-laptop:/home$ !180
wget http://www.bluntmen.com/ipw2200-1.1.4-inject.patch
–21:03:51– http://www.bluntmen.com/ipw2200-1.1.4-inject.patch
=> `ipw2200-1.1.4-inject.patch’
Resolviendo www.bluntmen.com…
Variables de entorno.
Las variables de entorno, son como explique en el anterior capitulo, porciones de memoria que el sistema coge para guardar valores específicos necesarios para el sistema. Si queremos saber las variables de entorno que hay en el sistema, solo tenéis que usar el comando ‘set‘.
rh3nt0n@rh3nt0n-laptop:/home$ set | more
BASH=/bin/bash
BASH_ARGC=()
BASH_ARGV=()
BASH_COMPLETION=/etc/bash_completion
BASH_COMPLETION_DIR=/etc/bash_completion.d
BASH_LINENO=()
BASH_SOURCE=()
……..
Para ejecutar una variable de entorno solo hay que citarla de esta manera:
rh3nt0n-laptop
las variables siempre se citan con el signo del dólar delante $, y es de resaltar que las variables predeterminadas del sistema, suelen estar en mayúsculas .
Nosotros podemos creas variables de entorno, las cuales pueden ejecutarse en la shell donde las hemos creado, o exportarlas para poder usarlas en cualquier terminal de la sesión que esta en marcha, aunque estas variables una vez reiniciado el sistema se pierden, esto es útil en servidores en los cuales rara vez se reinicia el sistema.
Para crear una variable de entorno seria de esta forma:
Ejemplo:
rh3nt0n@rh3nt0n-laptop:/home$ nombre=rh3nt0n
rh3nt0n@rh3nt0n-laptop:/home$ echo $edad
30
rh3nt0n@rh3nt0n-laptop:/home$ echo $nombre
rh3nt0n
rh3nt0n@rh3nt0n-laptop:/home$
Es recomendable a la hora de crear variables de entorno, que las que hagamos nosotros, las hagamos en minúsculas, así a la hora de borrar variables, no borraremos nada que no tengamos que borrar .
Las variables de entorno, cuando las crea un usuario, solo se ejecutan en la terminal donde se crean, para poder ejecutarlas en todas las terminales tendríamos que exportarlas:
Comando ‘export’
Esto haría que en la misma sesión en la que estamos, pero en otra terminal, se pueda ejecutar esa variable sin problemas.
Para borrar una variable determinada, solo habría que usar el comando ‘unset’ para ello:
comando ‘unset’
Hay variables como $PWD que se van actualizando dependiendo de donde nos encontremos y automáticamente.
Entrecomillado de caracteres en la shell.
Hay ordenes que requieren de argumentos los cuales habitualmente dependiendo de la forma que se quieren utilizar se usan unas comillas u otras.
echo ”$PATH ”
echo ‘ $PATH ‘
echo \$PATH
En el primer caso, ” ” las comillas son denominadas débiles, el comando o el argumento lo usa la shell tal y como esta escrito y lo ejecuta si viene al caso.
En el segundo caso, ‘ ‘ las comillas son denominadas fuertes ,lo cual quiere decir que la shell no actúa dentro de ellas, por lo tanto se toma literalmente el argumento.
En el tercer caso, el back slash ‘\’ se utiliza para escapar caracteres especiales como $ para que la shell tome el argumento como en el segundo caso.
Las comillas “ se usan en el caso de las variables para que se pueda usar un comando asignado a una variable:
Esta orden ejecutaría el comando date, al llamar a la variable ‘fecha’.
Redirección de la entrada/salida estándar.
La shell, toma información de la entrada estándar, (teclado) denominada stdin, cuando se ejecuta la orden dependiendo de como se ejecute, puede dar una salida valida o errónea, en caso de la salida valida la información por defecto la shell como salida estándar usa la pantalla, con lo cual nos muestra la información en la shell, en caso de que la ejecución del comando sea errónea, nos muestra la salida de error por defecto también por la pantalla y nos la muestra por la shell, aunque parezca en principio que tanto la salida estándar como la salida estándar de errores es lo mismo, no lo son, solo tienen por defecto asignado que enseñen la información por la pantalla .
Estas salidas, se pueden redireccionar, así mismo también la entrada estándar, o bien para que un comando tome los argumentos o sea la entrada de datos de un fichero o que la salida de un comando sea el argumento de otro, o que esa salida salga por la impresora, se imprima en un fichero etc .
Lo mejor es que lo veamos gráficamente:
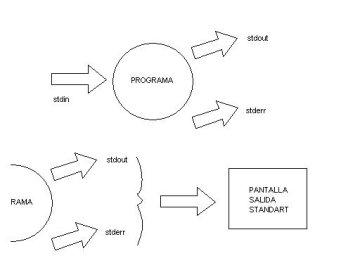
Formas de redireccionar la entrada estándar ‘stdin’.
el signo ‘<‘ cambia la entrada estándar.
ejemplos:
El anterior comando tomaría como argumento para el comando mail, el contenido del fichero carta.txt.
El anterior comando tomaría como argumento para el comando ejecutado, el contenido de fichero.
Formas de redireccionar la salida stantdart ‘stdout’ .
El signo ‘>’ redirecciona la salida estándar, creando el fichero si no existe y sobre escribiendo el archivo si existe.
comando > fichero
comando > contenido
comando > argumentos
comando > /dev/dispositivo
El comando anterior, redireccionaria la salida del comando a el fichero stdout
La salida estándar de errores, también puede redireccionarse, ya que si el comando ejecutado, aun teniendo la salida estándar redireccionada a el sitio que sea que no sea la salida estándar, si ese comando falla, la salida de errores la muestra por pantalla.
Para que esto no ocurra si no es nuestro deseo, o bien capturar en un fichero las posibles salidas de error, se usa ‘2>’ lo cual hace lo mismo que con la anterior opción hacia con la salida estándar.
Este comando mostraría en caso de que la ejecución fuera correcta, por la pantalla, salida estándar de errores. y en caso de que hubiera algún error, la salida de error la mostraría en el fichero stderr.
En conjunción ,seria algo como esto:
Esta sintaxis, redireccionaria la salida del comando en caso de que fuera correcto, a el archivo stdout, en caso de que fallara enviaría la salida de error a el fichero stderr.
Cuando no queremos que el archivo, a sabiendas de que existe, se sobrescriba, se utiliza el mayor que doble ‘>>’ de esta forma:
El anterior comando añadiría el texto hola mundo a el fichero.txt sin sobrescribirlo.
esto ocurre de igual manera con la salida de errores, pero de este modo:
Como se podrá apreciar, el comando echo esta mal escrito, pero la salida de errores se redireccionaria a el fichero errores.txt, en lugar de mostrarla por la pantalla.
rh3nt0n@rh3nt0n-laptop:~$ cat errores.txt
bash: eco: orden no encontrada
rh3nt0n@rh3nt0n-laptop:~$
Redirección a dispositivos ‘especiales’
Se pueden redireccionar salidas muy extensas, o salidas de errores a el dispositivo ‘/dev/null’, para evitar colapsar de información la salida estándar, o simplemente por que no nos interese ver esa salida. Este dispositivo es denominado ‘agujero negro’ ya que lo que es redireccionado allí, no se puede recuperar.
Ejemplo de uso:
Aquí cabe resaltar el uso del comando ‘time’, el cual tiene la peculiaridad de mostrar su salida estándar, por la salida de errores. En el siguiente ejemplo ,este comando se encarga de cronometrar el tiempo que tarda en ejecutarse el comando junto al que se ejecuta, mostrando la salida por pantalla y enviando la salida del comando a ejecutar a el dispositivo /dev/null.
ls: /etc/cups/ssl: Permiso denegado
ls: /etc/ssl/private: Permiso denegado
real 0m0.382s
user 0m0.024s
sys 0m0.012s
rh3nt0n@rh3nt0n-laptop:~$
Los filtros de búsqueda.
Los filtros de búsqueda son una utilidad muy interesante a la hora de buscar palabras comandos etc de forma ordenada y desechando lo que no nos interesa .
vamos a ver algunos comandos de búsqueda interesantes:
Comando “sort” sin opciones, ordena líneas de texto alfabéticamente aunque sean números.
opciones:
-n ordena números ” 1 2 3 4 ”
-t: define delimitador de campos
+(n) n de número, para elegir que columna queremos ver primero.
-F no considera mayúsculas o minúsculas.
-r invierte la salida normal.
Comando “grep”, busca líneas de texto en un archivo o salida de comando especificada.
sintaxis: grep patrón fichero
ejemplo de otro uso:
dmesg argumento | grep
opciones:
-v busca todas las líneas que no contienen el patrón
-i no considera mayúsculas de minúsculas .
-n numera las líneas que contienen el patrón especificado.
Comando “wc” ‘word count’ cuenta palabras la salida normal sin parámetros saca tres columnas:
sintaxis: wc [opciones] fichero
1º cantidad de líneas del fichero .
2º cantidad de palabras.
3º cantidad de caracteres.
opciones:
-l número de líneas únicamente
-w número de palabras únicamente
-c número de caracteres únicamente
Ejemplo de redirección con este comando:
Iniciación a los procesos.
Los procesos no son mas que los programas que se están ejecutando, cada procesador puede ejecutar solo un proceso cada vez que actúa. existen multitud de estados de los procesos, pero a groso modo podríamos destacar estos cuatro:
Los procesos pueden estar en varios estados:
Estado runing – solo puede haber un proceso runing o funcionando.
Estado preparado – son procesos que están preparados para ser ejecutados por el procesador.
Estado dormido – son procesos que han acabado, pero pueden ser llamados otra vez a funcionar.
Estado zombie – son procesos como su propio nombre indica, que al no acabar bien, siguen en memoria sin borrarse.
Esto se aprecia mejor con el siguiente grafico:
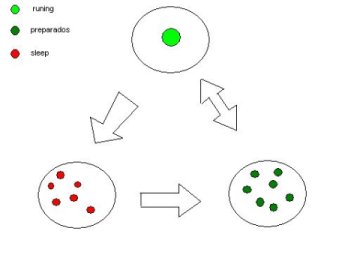
Comandos de información de procesos.
Comando “ps” este comando sirve para ver los procesos que se están ejecutando. Esto es muy útil para dar preferencias a algún proceso determinado, matar procesos, en definitiva conocer los PID de los procesos, para poder mandarles señales entre otras cosas .
La forma mas habitual de usar este comando es con las opciones a y x.
a para ver todos los procesos y x que muestre cuales se están ejecutando.
sintaxis: ps ax
rh3nt0n@rh3nt0n-laptop:~$ ps ax
PID TTY STAT TIME COMMAND
1 ? S 0:01 init [2]
2 ? SN 0:00 [ksoftirqd/0]
3 ? S 0:00 [watchdog/0]
4 ? S< 0:00 [events/0]
5 ? S< 0:00 [khelper]
6 ? S< 0:00 [kthread]
8 ? S< 0:00 [kblockd/0]
9 ? S< 0:00 [kacpid]
10 ? S< 0:00 [kacpid-work-0]
162 ? S 0:00 [pdflush]
163 ? S 0:00 [pdflush]
165 ? S< 0:00 [aio/0]
164 ? S 0:00 [kswapd0]
766 ? ………………
La primera columna de la salida del comando anterior muestra el PID del proceso ,todos los procesos tienen un PID del proceso, no es mas que un número identificador, para poder mandarle señal a cada proceso ejecutandose desde la consola.
La segunda columna indica la consola virtual donde se esta ejecutando el proceso, si no tiene aparece un signo de interrogacion ‘?’.
La tercera columna indica en el estado en el que se encuentra el proceso:
s —- dormido
r —- runing o corriendo
z —- zombie
t —– detenido
comando útil:
Busca y filtra el proceso buscado.
La cuarta columna, indica el tiempo que lleva ejecutándose el proceso.
Los procesos pueden recibir señales a través de la terminal, para interactuar con ellos .
Pueden trabajar como he explicado anteriormente en el front-ground, de forma visible en la terminal, y en el back-ground, de forma transparente, para nosotros desde la terminal.
Cuando un proceso recibe una señal desde la terminal, puede reaccionar de tres maneras diferentes:
1º puede ignorar la señal .
2º puede interpretar la señal .
3º puede aceptar que se encargue de el, el kernel .
Señales a los procesos.
Comando “kill” en principio mata el proceso, con opciones puede hacer reiniciar procesos dormidos.
sintaxis: kill -señal PID
Señales mas importantes:
señal -1 para que se reinicie un proceso, si no se puede, el sistema lo mata .
señal -2 interrupción
señal -3 para que el proceso acabe, pero sin errores .
señal -9 para el proceso, y el proceso no puede ignorar esta orden.
señal -15 es lo mismo que ejecutar kill sin opciones es como decirle al proceso ‘cuando puedas cierra’, esta señal puede ser ignorada por el proceso .
Comando ‘nohup’ Ejecuta la orden ignorando las señales de colgar, sirve para que las ordenes sigan funcionando, aunque salgamos de la terminal.
Sintaxis: nohup orden [argumento]
Cabe resaltar que cuando la shell deja un comando funcionando y salimos de ella lo hereda init.
Para ver los procesos y los niveles de ejecución existe el comando ‘top’, este comando muestra de forma dinámica los procesos que se ejecutan en el sistema:
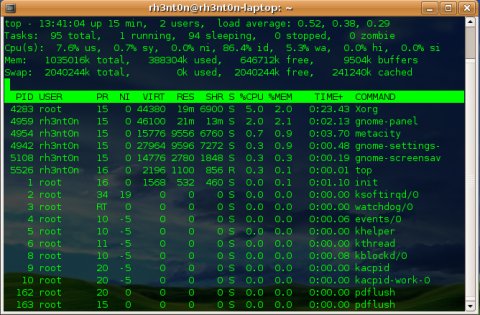
Esta aplicación (parecida a el visor de procesos de Windows) nos es muy útil para interactuar con los procesos, a la hora de mandar señales, y dar prioridades a uno u otro proceso .
Prioridades de los procesos.
Podemos asignar prioridades de ejecución a los procesos, si queremos que un programa tenga mas prioridad o menos, podemos bajarle o subirle el nivel de ejecución con el comando “nice”.
Comando “nice”
Este comando asigna nivel de ejecución a los procesos, por defecto asigna el valor 10.
sintaxis: nice [valor] orden [argumentos]
Los valores de nivel de ejecución van de el +19 al -19 siendo el de menor valor ‘-19’ el que mas prioridad tiene de ejecucion.
Los valores del -0 al -19 solo puede asignarlo el usuario root.
Comando “renice”.
Este comando repone el nivel de ejecución, a un procesos que este ejecutándose.
Sintaxis: renice [valor] número PID
Comando “sleep”.
Este comando duerme el proceso deseado ‘x‘ segundos especificados.
Sintaxis: sleep [tiempo] [opción] [orden]
Opciones:
-s tiempo en segundos (por defecto)
-h tiempo en horas.
-d tiempo en días.
Comando “jobs”. Muestra los procesos que se ejecutan en el back-ground.
Para usar este comando y los siguientes, nos viene muy bien el comando anteriormente citado “top“, ya que debemos apoyarnos en el IDE de proceso “PID“, para poder interactuar con los procesos en back-ground.
[2] 6521
rh3nt0n@rh3nt0n-laptop:~$ jobs
[1]+ Stopped yes >/dev/null
[2]- Running yes >/dev/null &
rh3nt0n@rh3nt0n-laptop:~$
Comando “fg”. Lleva un comando ejecutándose en back-ground, al front-ground.
Sintaxis: fg [PID de proceso]
yes >/dev/null
Comando “bg”. Relanza un proceso dormido, ejecutándolo en el back-ground.
Sintaxis: bg [PID del proceso dormido]
rh3nt0n@rh3nt0n-laptop:~$ jobs
[1]- Stopped yes >/dev/null
[2]+ Stopped yes >/dev/null
rh3nt0n@rh3nt0n-laptop:~$ bg 2
[2]+ yes >/dev/null &
rh3nt0n@rh3nt0n-laptop:~$ jobs
[1]+ Stopped yes >/dev/null
[2]- Running yes >/dev/null &
rh3nt0n@rh3nt0n-laptop:~$
En este punto, recuerdo que para matar un proceso conociendo su PID podemos usar lo siguiente:
Sintaxis: kill “% PID”
rh3nt0n@rh3nt0n-laptop:~$ jobs
[1]+ Stopped yes >/dev/null
[2]- Terminado yes >/dev/null
rh3nt0n@rh3nt0n-laptop:~$
también recuerdo, como lanzar un proceso en el back-ground.
Sintaxis: orden [argumentos] &